Speech To Text
|
|
Converts live speech to text. |
This is useful for routing contacts on the basis of their spoken words and phrases.
A third-party speech-to-text provider uses live speech to create an array of text interpretations and assigns a percentage confidence value to each. The action cell stores the first three interpretations that match or exceed a confidence threshold of your choice. You can then use or manipulate any of these text interpretations for routing contacts.
Properties
Speech To Text Section
|
Option |
Description |
| Select the third-party speech-to-text provider to use. If only one provider is configured for use in your deployment, this option is not available and the fields below will be those for your configured provider. | |
|
Language |
Select the spoken language to detect. With the Select Language option selected, choose the language from the Language drop-down list. Or select Use Dynamic Language, then drag and drop the string parameter that will provide the language at run-time into the Language field that appears. |
|
Silence Duration |
Set the period of silence, which when detected at any point in the speech, will end the interpretation. |
|
Set the duration after which the interpretation will end. |
|
|
Confidence Threshold (%) |
Specify a percentage threshold value. Interpretations matching or exceeding this value will be written to the interpretation variables (see below). |
Media Section
|
Option |
Description |
|
Select Media List/ Use Dynamic Media List/ Media Lists/ Introduction Prompt/ Select Media Item/ Use Dynamic Media Item/ Introduction Prompt |
Select the media file to use for prompting the caller to speak. |
Interpretations Section
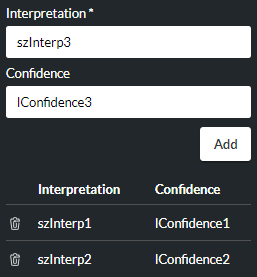
Use this section to store up to three interpretation/confidence variable pairs returned by the speech-to-text provider. You can then use subsequent action cells to route contacts according to these stored interpretations.
|
Option |
Description |
|
Interpretation/Confidence |
In the Interpretation field, enter the string variable in which to store an interpretation of up to 2048 characters (including spaces) that has a confidence level matching or exceeding the value specified in the Confidence Threshold (%) property. Then, in the Confidence field, enter the integer variable in which to store the confidence value assigned to the interpretation (as returned by the speech-to-text provider). Click ADD. Build your list of up to three Interpretation and Confidence variable pairs:
|
Advanced Options Section
|
Option |
Description |
|
Single-Utterance Mode |
The selected check box (default setting) means that speech-to-text interpretation will end when FLOW deems a single coherent utterance to have been spoken. Note: with the option enabled, the values specified in the Silence Duration and Timeout fields above still apply as the caller may be silent during an utterance or a single utterance may extend beyond the value specified in Timeout. Clear the check box if you want speech-to-text interpretation to be governed by the Silence Duration and Timeout fields only, rather than allow FLOW to determine when an utterance has been spoken. This allows you to include multiple utterances in the speech. |
|
Class Token |
Specify a class token identifier from the list of tokens listed in the Google Documentation (all class token identifiers are prefixed with the '$' character). This must be provided as a literal preceded by =, or a variable of type string.
A class token is used to improve the transcription of an expected spoken word or phrase. For example, using the class token $Time will transcribe the spoken words "twenty to five" as "4:40" rather than the text 'twenty to five". Note: as class-token support is provided by a third-party application, transcription to the desired text is not guaranteed. |
|
Select this if, in the event of the caller hanging up (and script execution ending), you want the action cell to transcribe the part of the speech that was spoken prior to the hang up for use later on. For example, you might use it for reporting purposes through a clear down handler script that is invoked when the main script's execution ends on call hang up. Leave the check box unselected if there is no need for the detected part of the speech to be transcribed. For example, a transcription that is intended solely for routing purposes such as to a queue serves no purpose if the caller hangs up before call execution reaches the end of the script. |

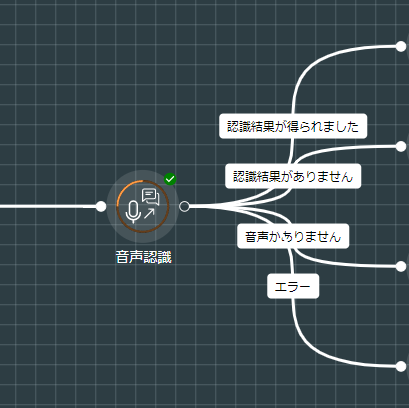
Exit Points
|
Exit Point |
Description |
|
Interpretation Found |
This is taken if the speech-to-text provider returned at least one interpretation matching or exceeding the value in the Confidence Threshold (%) property. |
|
Interpretation Not Found |
This is taken if the speech-to-text provider did NOT return an interpretation matching or exceeding the value in the Confidence Threshold (%) property. |
|
No Audio Present |
This is taken if no audio was detected within the time set in the Timeout property. |
|
Error |
This is taken if an internal system error occurred. |