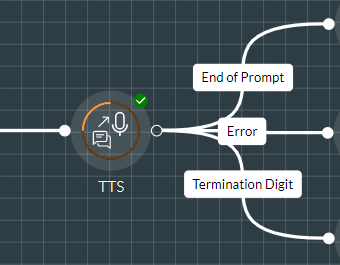
TTS
|
|
Text to Speech. Reads out textual phrases to the caller. |
When used in conjunction with Play Media action cells, you can build an audio message containing a combination of generic and customer-specific information stored in variables. For example:
|
Play Media (Dear.wav) |
TTS |
Play Media (Entered.wav) |
TTS |
|
"Dear" |
"John" |
"You have just entered" |
"one, six, one, zero, nine" |
Language options are available as licensed on your system.
For a list of language and voice codes supported by Google, use the following link:
https://cloud.google.com/text-to-speech/docs/voices
For a list of language and voice codes supported by Microsoft Azure, use the following link:
https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support?tabs=tts
Properties
TTS Section
|
Option |
Description |
|
Select the text-to-speech model to use. The 'brain TTS' option provides AI enhanced features from a number of providers. The list may display any custom models that have been built as well as any third-party TTS providers that have been provisioned for you. Selecting the 'brain TTS' option allows you to change the speed of the converted speech if desired. See the Advanced Options section further below. |
|
|
This applies to the brain TTS model only. Select either 'Google' or 'Azure' as the AI provider to use. |
|
|
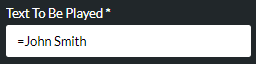
Text To Be Played |
Enter the number, word, or phrase as a literal preceded by =:
or as a string variable:
|

Options Section
Use this to specify language, voice, and cut-through options.
|
Option |
Description |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
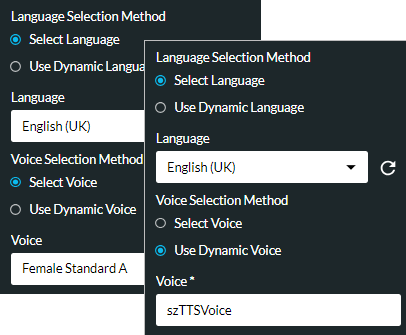
Language Selection Method/ Language/ Voice Selection Method/ Voice |
For the 'Standard' text-to-speech model, select the language (subject to licence). For the 'brain TTS' text-to-speech model, with the Select language option selected, choose the language from the Language options list (for example, 'English (UK)') and then select either the Select Voice option to choose a voice (for example, 'Female Standard A') or select Use Dynamic Voice to use a string variable containing the name of the voice.
Alternatively, use the Use Dynamic Language option to use variables for both the language and the voice.
If you are using variables, ensure that the language name and voice name values populating the variables correspond to the language code and voice code defined by the AI provider. For a list of supported language and voice codes see the references provided earlier. As an example, both Google and Azure use the language code 'en-GB' for UK English; Google uses the voice code 'en-GB-Standard-A' for the standard female voice in UK English, and Azure uses the voice code 'en-GB-SoniaNeural' for the 'Sonia' voice. Note: the voices are subject to change by the AI provider. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
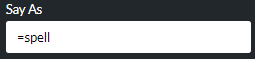
For the 'Standard' text-to-speech model, either leave the field blank or enter a value denoting how the text or variable should be rendered when spoken. The effect of this for the supported data types is shown in the following table:
For example:
For the 'brain TTS' text-to-speech model, select one of the available options. Note: some options may not be available for some providers.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Enable Cut Through |
Select this and then the keys that callers can press to stop playing the speech before it ends.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


Advanced Options Section
This is displayed for the 'brain TTS' text-to-speech model only.
|
Option |
Description |
|
Pitch |
Use this if you want to change the pitch of the converted speech. Move the slider to the right for a higher-pitched voice, or to the left for a lower-pitched (deeper) voice. |
|
Rate |
Use this if you want to change the speed of the converted speech. The default value of 100% represents the normal speed of human speech. Move the slider to the right to speed up the voice, or to the left to slow it down. Changing the rate does not distort the speech. |
Exit Points
|
Exit Point |
Description |
|
End of Prompt |
This is taken when the prompt has played successfully. |
|
Error |
This is taken if an error has occurred. |
|
Termination Digit |
This is taken if the caller presses a termination key defined by the Enable Cut Through property. |